defragmentation
Good morning, hackers! Been a while. It used to be that I had long blocks of uninterrupted time to think and work on projects. Now I have two kids; the longest such time-blocks are on trains (too infrequent, but it happens) and in a less effective but more frequent fashion, after the kids are sleeping. As I start writing this, I'm in an airport waiting for a delayed flight -- my first since the pandemic -- so we can consider this to be the former case.
It is perhaps out of mechanical sympathy that I have been using my reclaimed time to noodle on a garbage collector. Managing space and managing time have similar concerns: how to do much with little, efficiently packing different-sized allocations into a finite resource.
I have been itching to write a GC for years, but the proximate event that pushed me over the edge was reading about the Immix collection algorithm a few months ago.
on fundamentals
Immix is a "mark-region" collection algorithm. I say "algorithm" rather than "collector" because it's more like a strategy or something that you have to put into practice by making a concrete collector, the other fundamental algorithms being copying/evacuation, mark-sweep, and mark-compact.
To build a collector, you might combine a number of spaces that use different strategies. A common choice would be to have a semi-space copying young generation, a mark-sweep old space, and maybe a treadmill large object space (a kind of copying collector, logically; more on that later). Then you have heuristics that determine what object goes where, when.
On the engineering side, there's quite a number of choices to make there too: probably you make some parts of your collector to be parallel, maybe the collector and the mutator (the user program) can run concurrently, and so on. Things get complicated, but the fundamental algorithms are relatively simple, and present interesting fundamental tradeoffs.
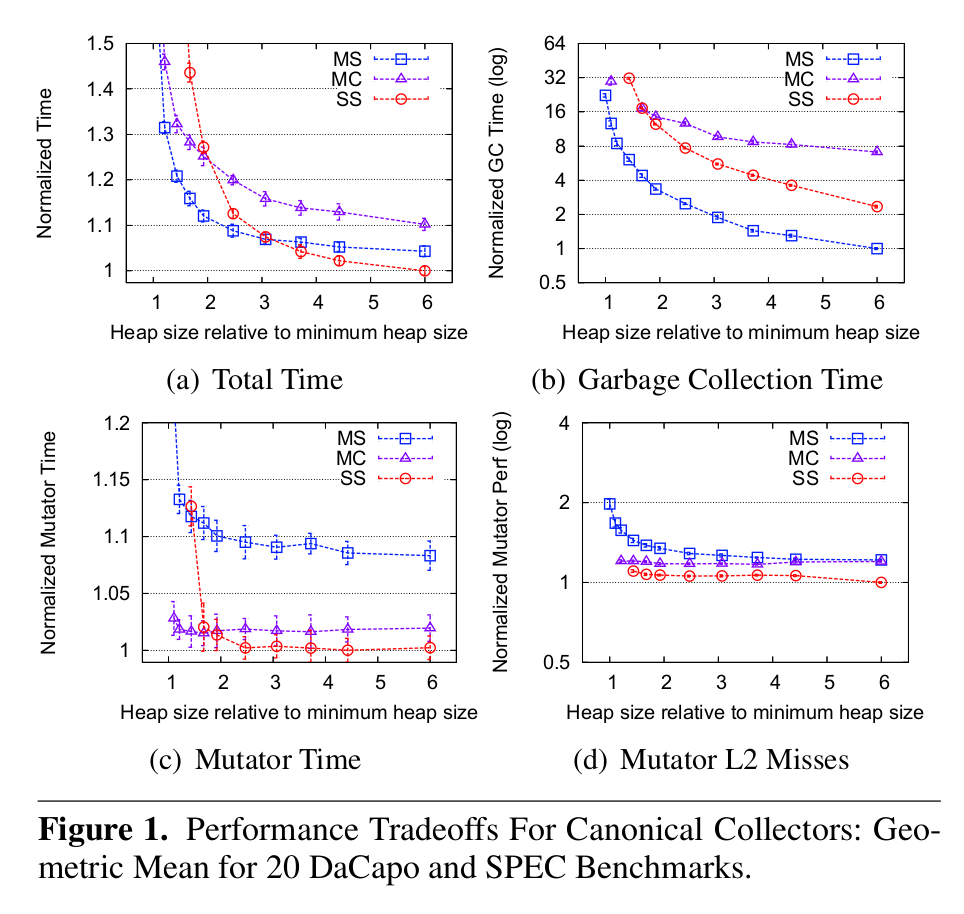
figure 1 from the immix paper
For example, mark-compact is most parsimonious regarding space usage -- for a given program, a garbage collector using a mark-compact algorithm will require less memory than one that uses mark-sweep. However, mark-compact algorithms all require at least two passes over the heap: one to identify live objects (mark), and at least one to relocate them (compact). This makes them less efficient in terms of overall program throughput and can also increase latency (GC pause times).
Copying or evacuating spaces can be more CPU-efficient than mark-compact spaces, as reclaiming memory avoids traversing the heap twice; a copying space copies objects as it traverses the live object graph instead of after the traversal (mark phase) is complete. However, a copying space's minimum heap size is quite high, and it only reaches competitive efficiencies at large heap sizes. For example, if your program needs 100 MB of space for its live data, a semi-space copying collector will need at least 200 MB of space in the heap (a 2x multiplier, we say), and will only run efficiently at something more like 4-5x. It's a reasonable tradeoff to make for small spaces such as nurseries, but as a mature space, it's so memory-hungry that users will be unhappy if you make it responsible for a large portion of your memory.
Finally, mark-sweep is quite efficient in terms of program throughput, because like copying it traverses the heap in just one pass, and because it leaves objects in place instead of moving them. But! Unlike the other two fundamental algorithms, mark-sweep leaves the heap in a fragmented state: instead of having all live objects packed into a contiguous block, memory is interspersed with live objects and free space. So the collector can run quickly but the allocator stops and stutters as it accesses disparate regions of memory.
allocators
Collectors are paired with allocators. For mark-compact and copying/evacuation, the allocator consists of a pointer to free space and a limit. Objects are allocated by bumping the allocation pointer, a fast operation that also preserves locality between contemporaneous allocations, improving overall program throughput. But for mark-sweep, we run into a problem: say you go to allocate a 1 kilobyte byte array, do you actually have space for that?
Generally speaking, mark-sweep allocators solve this problem via freelist allocation: the allocator has an array of lists of free objects, one for each "size class" (say 2 words, 3 words, and so on up to 16 words, then more sparsely up to the largest allocatable size maybe), and services allocations from their appropriate size class's freelist. This prevents the 1 kB free space that we need from being "used up" by a 16-byte allocation that could just have well gone elsewhere. However, freelists prevent objects allocated around the same time from being deterministically placed in nearby memory locations. This increases variance and decreases overall throughput for both the allocation operations but also for pointer-chasing in the course of the program's execution.
Also, in a mark-sweep collector, we can still reach a situation where there is enough space on the heap for an allocation, but that free space broken up into too many pieces: the heap is fragmented. For this reason, many systems that perform mark-sweep collection can choose to compact, if heuristics show it might be profitable. Because the usual strategy is mark-sweep, though, they still use freelist allocation.
on immix and mark-region
Mark-region collectors are like mark-sweep collectors, except that they do bump-pointer allocation into the holes between survivor objects.
Sounds simple, right? To my mind, though the fundamental challenge in implementing a mark-region collector is how to handle fragmentation. Let's take a look at how Immix solves this problem.
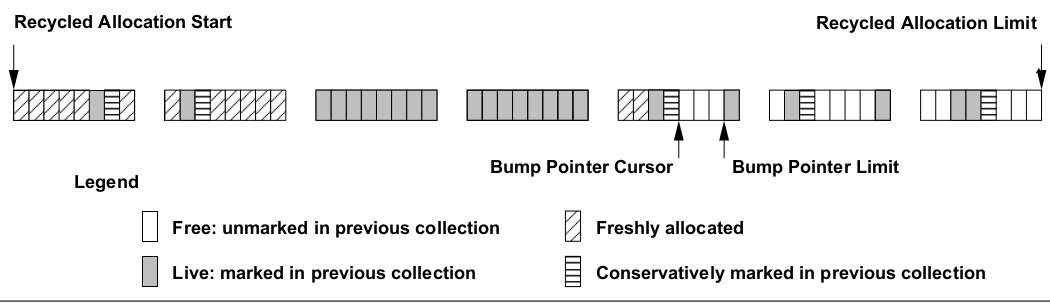
part of figure 2 from the immix paper
Firstly, Immix partitions the heap into blocks, which might be 32 kB in size or so. No object can span a block. Block size should be chosen to be a nice power-of-two multiple of the system page size, not so small that common object allocations wouldn't fit. Allocating "large" objects -- greater than 8 kB, for Immix -- go to a separate space that is managed in a different way.
Within a block, Immix divides space into lines -- maybe 128 bytes long. Objects can span lines. Any line that does not contain (a part of) an object that survived the previous collection is part of a hole. A hole is a contiguous span of free lines in a block.
On the allocation side, Immix does bump-pointer allocation into holes. If a mutator doesn't have a hole currently, it scans the current block (obtaining one if needed) for the next hole, via a side-table of per-line mark bits: one bit per line. Lines without the mark are in holes. Scanning for holes is fairly cheap, because the line size is not too small. Note, there are also per-object mark bits as well; just because you've marked a line doesn't mean that you've traced all objects on that line.
Allocating into a hole has good expected performance as well, as it's bump-pointer, and the minimum size isn't tiny. In the worst case of a hole consisting of a single line, you have 128 bytes to work with. This size is large enough for the majority of objects, given that most objects are small.
mitigating fragmentation
Immix still has some challenges regarding fragmentation. There is some loss in which a single (piece of an) object can keep a line marked, wasting any free space on that line. Also, when an object can't fit into a hole, any space left in that hole is lost, at least until the next collection. This loss could also occur for the next hole, and the next and the next and so on until Immix finds a hole that's big enough. In a mark-sweep collector with lazy sweeping, these free extents could instead be placed on freelists and used when needed, but in Immix there is no such facility (by design).
One mitigation for fragmentation risks is "overflow allocation": when allocating an object larger than a line (a medium object), and Immix can't find a hole before the end of the block, Immix allocates into a completely free block. So actually mutator threads allocate into two blocks at a time: one for small objects and medium objects if possible, and the other for medium objects when necessary.
Another mitigation is that large objects are allocated into their own space, so an Immix space will never be used for blocks larger than, say, 8kB.
The other mitigation is that Immix can choose to evacuate instead of mark. How does this work? Is it worth it?
stw
This question about the practical tradeoffs involving evacuation is the one I wanted to pose when I started this article; I have gotten to the point of implementing this part of Immix and I have some doubts. But, this article is long enough, and my plane is about to land, so let's revisit this on my return flight. Until then, see you later, allocators!
One response
Comments are closed.
The inko language uses immix written in Rust.
https://gitlab.com/inko-lang/inko