high-performance packet filtering with pflua
Greets! I'm delighted to be able to announce the release of Pflua, a high-performance packet filtering toolkit written in Lua.
Pflua implements the well-known libpcap packet filtering language, which we call pflang for short.
Unlike other packet filtering toolkits, which tend to use the libpcap library to compile pflang expressions bytecode to be run by the kernel, Pflua is a completely new implementation of pflang.
why lua?
At this point, regular readers are asking themselves why this Schemer is hacking on a Lua project. The truth is that I've always been looking for an excuse to play with the LuaJIT high-performance Lua implementation.
LuaJIT is a tracing compiler, which is different from other JIT systems I have worked on in the past. Among other characteristics, tracing compilers only emit machine code for branches that are taken at run-time. Tracing seems a particularly appropriate strategy for the packet filtering use case, as you end up with linear machine code that reflects the shape of actual network traffic. This has the potential to be much faster than anything static compilation techniques can produce.
The other reason for using Lua was because it was an excuse to hack with Luke Gorrie, who for the past couple years has been building the Snabb Switch network appliance toolkit, also written in Lua. A common deployment environment for Snabb is within the host virtual machine of a virtualized server, with Snabb having CPU affinity and complete control over a high-performance 10Gbit NIC, which it then routes to guest VMs. The administrator of such an environment might want to apply filters on the kinds of traffic passing into and out of the guests. To this end, we plan on integrating Pflua into Snabb so as to provide a pleasant, expressive, high-performance filtering facility.
Given its high performance, it is also reasonable to deploy Pflua on gateway routers and load-balancers, within virtualized networking appliances.
implementation
Pflua compiles pflang expressions to Lua source code, which are then optimized at run-time to native machine code.
There are actually two compilation pipelines in Pflua. The main one is fairly traditional. First, a custom parser produces a high-level AST of a pflang filter expression. This AST is lowered to a primitive AST, with a limited set of operators and ways in which they can be combined. This representation is then exhaustively optimized, folding constants and tests, inferring ranges of expressions and packet offset values, hoisting assertions that post-dominate success continuations, etc. Finally, we residualize Lua source code, performing common subexpression elimination as we go.
For example, if we compile the simple Pflang expression ip or ip6 with the default compilation pipeline, we get the Lua source code:
return function(P,length)
if not (length >= 14) then return false end
do
local v1 = ffi.cast("uint16_t*", P+12)[0]
if v1 == 8 then return true end
do
do return v1 == 56710 end
end
end
end
The other compilation pipeline starts with bytecode for the Berkeley packet filter VM. Pflua can load up the libpcap library and use it to compile a pflang expression to BPF. In any case, whether you start from raw BPF or from a pflang expression, the BPF is compiled directly to Lua source code, which LuaJIT can gnaw on as it pleases. Compiling ip or ip6 with this pipeline results in the following Lua code:
return function (P, length)
local A = 0
if 14 > length then return 0 end
A = bit.bor(bit.lshift(P[12], 8), P[12+1])
if (A==2048) then goto L2 end
if not (A==34525) then goto L3 end
::L2::
do return 65535 end
::L3::
do return 0 end
error("end of bpf")
end
We like the independence and optimization capabilities afforded by the native pflang pipeline. Pflua can hoist and eliminate bounds checks, whereas BPF is obligated to check that every packet access is valid. Also, Pflua can work on data in network byte order, whereas BPF must convert to host byte order. Both of these restrictions apply not only to Pflua's BPF pipeline, but also to all other implementations that use BPF (for example the interpreter in libpcap, as well as the JIT compilers in the BSD and Linux kernels).
However, though Pflua does a good job in implementing pflang, it is inevitable that there may be bugs or differences of implementation relative to what libpcap does. For that reason, the libpcap-to-bytecode pipeline can be a useful alternative in some cases.
performance
When Pflua hits the sweet spots of the LuaJIT compiler, performance screams.
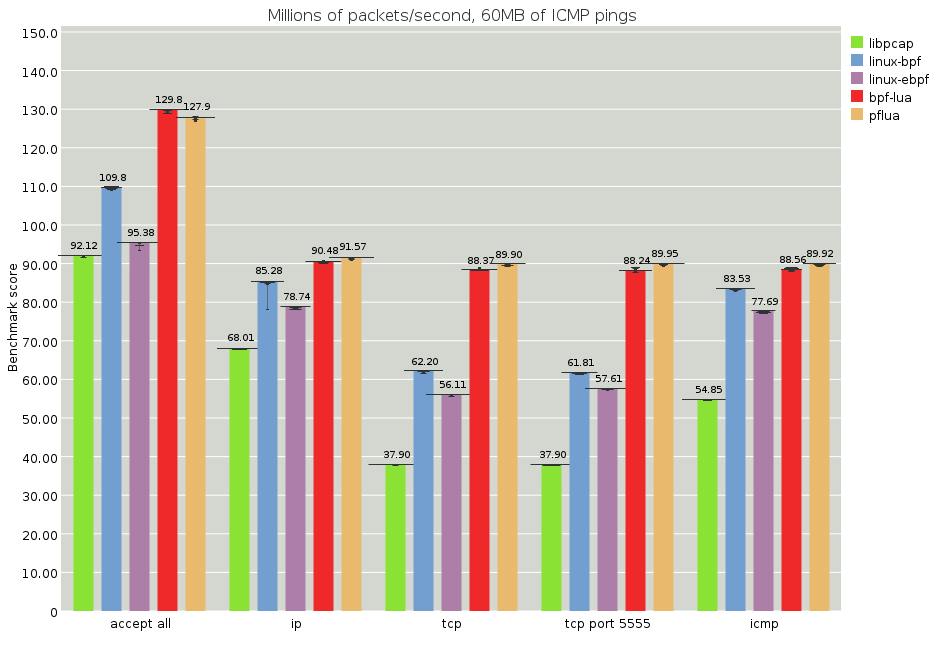
(full image, analysis)
This synthetic benchmark runs over a packet capture of a ping flood between two machines and compares the following pflang implementations:
libpcap: The user-space BPF interpreter from libpcap
linux-bpf: The old Linux kernel-space BPF compiler from 2011. We have adapted this library to work as a loadable user-space module (source)
linux-ebpf: The new Linux kernel-space BPF compiler from 2014, also adapted to user-space (source)
bpf-lua: BPF bytecodes, cross-compiled to Lua by Pflua.
pflua: Pflang compiled directly to Lua by Pflua.
To benchmark a pflang implementation, we use the implementation to run a set of pflang expressions over saved packet captures. The result is a corresponding set of benchmark scores measured in millions of packets per second (MPPS). The first set of results is thrown away as a warmup. After warmup, the run is repeated 50 times within the same process to get multiple result sets. Each run checks to see that the filter matches the the expected number of packets, to verify that each implementation does the same thing, and also to ensure that the loop is not dead.
In all cases the same Lua program is used to drive the benchmark. We have tested a native C loop when driving libpcap and gotten similar results, so we consider that the LuaJIT interface to C is not a performance bottleneck. See the pflua-bench project for more on the benchmarking procedure and a more detailed analysis.
The graph above shows that Pflua can stream in packets from memory and run some simple pflang filters them at close to the memory bandwidth on this machine (100 Gbit/s). Because all of the filters are actually faster than the accept-all case, probably due to work causing prefetching, we actually don't know how fast the filters themselves can run. At any case, in this ideal situation, we're running at a handful of nanoseconds per packet. Good times!
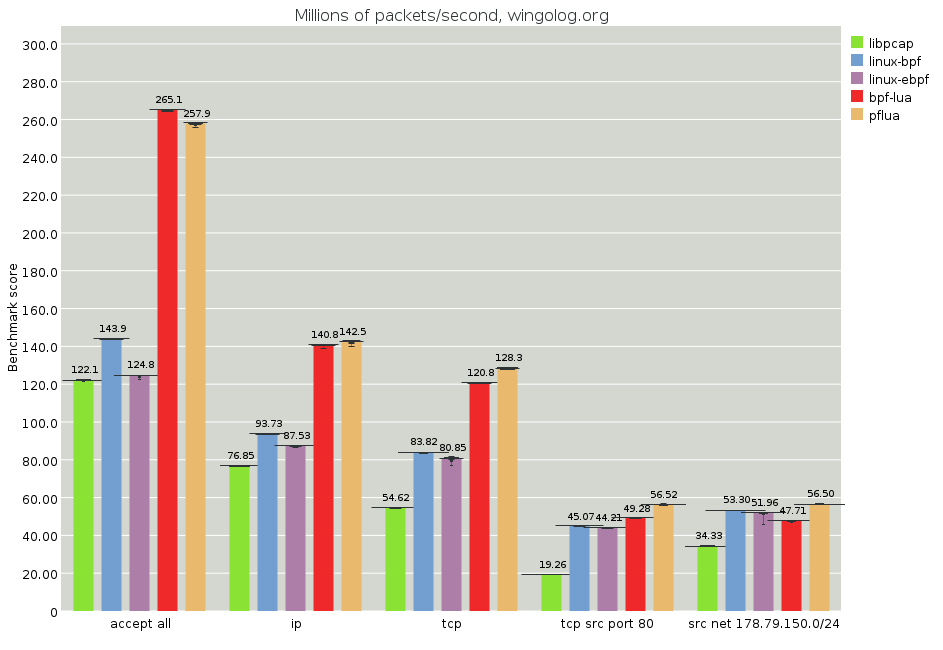
(full image, analysis)
It's impossible to make real-world tests right now, especially since we're running over packet captures and not within a network switch. However, we can get more realistic. In the above test, we run a few filters over a packet capture from wingolog.org, which mostly operates as a web server. Here we see again that Pflua beats all of the competition. Oddly, the new Linux JIT appears to fare marginally worse than the old one. I don't know why that would be.
Sadly, though, the last tests aren't running at that amazing flat-out speed we were seeing before. I spent days figuring out why that is, and that's part of the subject of my last section here.
on lua, on luajit
I implement programming languages for a living. That doesn't mean I know everything there is to know about everything, or that everything I think I know is actually true -- in particular, I was quite ignorant about trace compilers, as I had never worked with one, and I hardly knew anything about Lua at all. With all of those caveats, here are some ignorant first impressions of Lua and LuaJIT.
LuaJIT has a ridiculously fast startup time. It also compiles really quickly: under a minute. Neither of these should be important but they feel important. Of course, LuaJIT is not written in Lua, so it doesn't have the bootstrap challenges that Guile has; but still, a fast compilation is refreshing.
LuaJIT's FFI is great. Five stars, would program again.
As a compilation target, Lua is OK. On the plus side, it has goto and efficient bit operations over 32-bit numbers. However, and this is a huge downer, the result range of bit operations is the signed int32 range, not the unsigned range. This means that bit.band(0xffffffff, x) might be negative. No one in the history of programming has ever wanted this. There are sensible meanings for negative results to bit operations, but only if an argument was negative. Grr. Otherwise, Lua shares the same concerns as other languages whose numbers are defined as 64-bit doubles.
Sometimes people get upset that Lua starts its indexes (in "arrays" or strings) with 1 instead of 0. It's foreign to me, so it's sometimes a challenge, but it can work as well as anything else. The problem comes in when working with the LuaJIT FFI, which starts indexes with 0, leading me to make errors as I forget which kind of object I am working on.
As a language to implement compilers, Lua desperately misses a pattern matching facility. Otherwise, a number of small gripes but no big ones; tables and closures abound, which leads to relatively terse code.
Finally, how well does trace compilation work for this task? I offer the following graph.
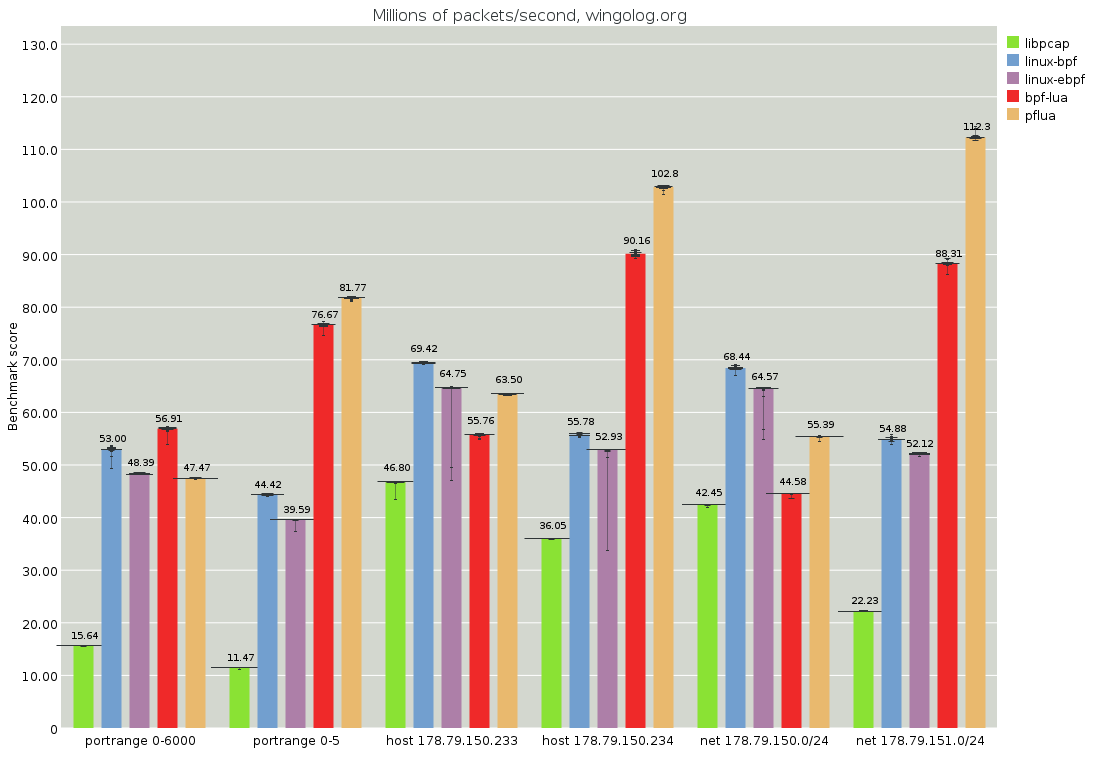
(full image, analysis)
Here the tests are paired. The first test of a pair, for example the leftmost portrange 0-6000, will match most packets. The second test of a pair, for example the second-from-the-left portrange 0-5, will reject all packets. The generated Lua code will be very similar, except for some constants being different. See portrange-0-6000.md for an example.
The Pflua performance of these filters is very different: the one that matches is slower than the one that doesn't, even though in most cases the non-matching filter will have to do more work. For example, a non-matching filter probably checks both src and dst ports, whereas a successful one might not need to check the dst.
It hurts to see Pflua's performance be less than the Linux JIT compilers, and even less than libpcap at times. I scratched my head for a long time about this. The Lua code is fine, and actually looks much like the BPF code. I had taken a look at the generated assembly code for previous traces and it looked fine -- some things that were not as good as they should be (e.g. a fair bit of conversions between integers and doubles, where these traces have no doubles), but things were OK. What changed?
Well. I captured the traces for portrange 0-6000 to a file, and dove in. Trace 66 contains the inner loop. It's interesting to see that there's a lot of dynamic checks in the beginning of the trace, although the loop itself is not bad (scroll down to see the word LOOP:), though with the double conversions I mentioned before.
It seems that trace 66 was captured for a packet whose src port was within range. Later, we end up compiling a second trace if the src port check fails: trace 67. The trace starts off with an absurd amount of loads and dynamic checks -- to a similar degree as trace 66, even though trace 66 dominates trace 67. It seems that there is a big penalty for transferring from one trace to another, even though they are both compiled.
Finally, once trace 67 is done -- and recall that all it has to do is check the destination port, and then update the counters from the inner loop) -- it jumps back to the top of trace 66 instead of the top of the loop, repeating all of the dynamic checks in trace 66! I can only think this is a current deficiency of LuaJIT, and not with trace compilation in general, although the amount of state transfer points to a lack of global analysis that you would get in a method JIT. I'm sure that values are being transferred that are actually dead.
This explains the good performance for the match-nothing cases: the first trace that gets compiled residualizes the loop expecting that all tests fail, and so only matching cases or variations incur the trace transfer-and-re-loop cost.
It could be that the Lua code that Pflua residualizes is in some way not idiomatic or not performant; tips in that regard are appreciated.
conclusion
I was going to pass some possible slogans by our marketing department, but we don't really have one, so I pass them on to you and you can tell me what you think:
"Pflua: A Totally Adequate Pflang Implementation"
"Pflua: Sometimes Amazing Performance!!!!1!!"
"Pflua: Organic Artisanal Network Packet Filtering"
Pflua was written by Igalians Diego Pino, Javier Muñoz, and myself for Snabb Gmbh, fine purveyors of high-performance networking solutions. If you are interested in getting Pflua in a Snabb context, we'd be happy to talk; drop a note to the snabb-devel forum. For Pflua in other contexts, file an issue or drop me a mail at [email protected]. Happy hackings with Pflua, the totally adequate pflang implementation!
9 responses
Comments are closed.
Well, 'ffi' is a global, 'bit' is a global. None of the most used functions (like ffi.cast) are made a local in an outer scope. Basic Lua performance tuning ...
Also, you're attempting to second-guess the optimizations of LuaJIT. That's not a good idea. E.g. storing the result of all array lookups in variables only serves to increase the set of live variables at trace transitions. Don't do that, the compiler knows better how (and when) to eliminate loads.
And in general: compile LuaJIT with -DLUAJIT_NUMMODE=2 (see src/Makefile) for this kind of workload. I already told that to the Snabb guys, but they are somewhat 'Beratungsresistent'. ;-)
--Mike
Thank you for stopping by, Mike! What a pleasure. Thank you also for LuaJIT, which has been a delight to play with.
For some reason I was thinking that ffi had special consideration in the JIT compiler in ways other than direct calls; I guess I was wrong there. Probably these are a bunch of rookie mistakes of someone used to method JITs coming to work with a different system. I'll give your ideas a go.
It's interesting to me to see that the things you need to do to make optimal code are different in method and trace JIT systems. I was somewhat surprised to see that (some subset of) the hoisted checks from one trace do not transfer over for subsequent traces.
Naively disabling the codegen-time CSE and caching globals in an outer scope does not seem to be a panacea for performance. I did that and captured a trace at https://gist.github.com/andywingo/ca53c62937324dade1f9. Performance numbers were similar. A few things stand out with this new trace:
1. Inter-trace state transfer is indeed down.
2. Some local names are probably a good idea; naively letting Lua have a go results in recomputation in child traces.
3. Local names for ffi.cast et al do not eliminate the need for dynamic checks, and the jumps from child traces back to the start of the trace with the loop will still cause dynamic checks to run; not all loop backedges have the same cost.
Again, caveats regarding ignorance and newbieness, &c.
Umm, that doesn't look right.
There seems to be stuff in the loop outside of the PF that has the same issues wrt. locals. Also, it's still using doubles all over the place.
I think the killer is that it now has allocations in some hot paths. Hard to say without enough context.
Use -jdump=+rs to get more info about sunk allocations and escaping locals.
Good point! There were a couple of ffi.cast calls in the loop. (For the record, the loop for the traces i was taking is here; the benchmark harness for the above comparisons is here.)
Thanks for the hint about -jdump=+rs; allocations are surely the issue. Will take a look.
Thanks for sharing the details Andy. This gives me hope that I can someday design my own langauges and use luajit as my backend for amazing speed without having to write my own cross-platform jit.
It's a shame that browser jits work so differently, but I'll be emitting a different language on those platforms anyway so I guess it's fine to require different optimization techniques.
Okay, I have an alternative slogan for you:
"PFLua: Performance! (If you know what that is..)"
SLOGAN: PFLua: Impedence Matching Wirespeeds to Processing
Tres Geek.
Have you looked at LPeg? It's great for pattern matching.
http://www.inf.puc-rio.br/~roberto/lpeg/